
:quality(80))
Data Engineering Jobs Skills Radar 2026: Emerging Frameworks, Tools & Technologies to Learn Now
Data is the new oil—and data engineers are the pipeline builders. In 2026, UK companies aren’t just collecting data—they’re streaming it, transforming it in real-time, and deploying it into AI and BI tools for instant decision-making. But all of this depends on one thing: highly skilled data engineers with a mastery of modern tools and frameworks.
Welcome to the Data Engineering Jobs Skills Radar 2026—your annual guide to the languages, platforms, and tools that are defining the future of data engineering jobs in the UK. Whether you're building data lakes, deploying pipelines, or scaling real-time analytics, this guide will keep your skills up to date with what employers really want.
Why Data Engineering Skills Are Shifting in 2026
Data engineering is evolving from legacy ETL and siloed data warehouses to modern, modular, cloud-native architectures.
UK hiring managers are seeking professionals who can:
Build scalable & reusable pipelines
Work with real-time & batch workflows
Enable analytics, ML, and BI teams through clean data
Deploy with CI/CD and infrastructure-as-code
Optimise costs and monitor data health across teams
Data engineers are no longer just behind-the-scenes operators—they are critical enablers of insight, automation, and AI.
Top Programming Languages for Data Engineering in 2026
1. Python
What it is: The dominant language for scripting, pipeline orchestration, and machine learning integration.
Why it matters: Python powers data transformations, APIs, orchestration logic, and AI model deployment.
Used by: Monzo, DeepMind, BBC, NHS data teams, fintechs.
Roles: Data Engineer, MLOps Engineer, Platform Developer.
Skills to pair: Pandas, PySpark, Airflow SDK, requests, SQLAlchemy.
2. SQL
What it is: The foundational language of querying and transforming structured data.
Why it matters: Still essential for transformations, metrics, testing, and BI integration.
Used by: Everyone—startups, banks, NHS, telcos, SaaS firms.
Roles: Analytics Engineer, Data Analyst, DataOps Lead.
Skills to pair: Window functions, CTEs, views, dbt, query optimisation.
3. Scala
What it is: JVM-based language often used in Apache Spark pipelines.
Why it matters: Critical in high-performance, distributed computing environments.
Used by: Enterprise data teams, finance firms, telecoms.
Roles: Spark Engineer, Real-Time Data Architect.
Skills to pair: Spark MLlib, Delta Lake, Kafka Streams.
4. Java
Why it matters: Used in streaming tools, Hadoop-based platforms, and backend integration.
Used by: Big banks, legacy Hadoop ecosystems, Kafka pipeline teams.
Roles: Data Platform Engineer, Middleware Developer.
5. Go (Golang)
Why it's rising: Great for writing data services, stream processors, and backend APIs.
Used by: Cloud-first data teams (e.g. Cloudflare, Segment).
Roles: Data Infrastructure Engineer, Microservice Architect.
Core Frameworks & Orchestration Tools to Learn
1. Apache Spark
What it is: A distributed computing engine for big data processing (batch & streaming).
Why it matters: Still the backbone of many large-scale data transformations.
Used by: Spotify, Sky, Deliveroo, major banks.
Roles: Spark Developer, Data Lake Engineer.
Skills to pair: PySpark, Spark Streaming, Delta Lake, Hadoop.
2. dbt (data build tool)
What it is: SQL-first transformation tool for modern data stacks.
Why it matters: Shifts transformation logic closer to analysts and adds testing, docs, lineage.
Used by: Monzo, Gousto, Wise, SaaS scale-ups.
Roles: Analytics Engineer, DataOps Developer.
Skills to pair: dbt Cloud, Jinja templating, CI/CD pipelines.
3. Airflow / Prefect
What it is: DAG-based orchestration tools for managing task dependencies and scheduling.
Why it matters: Run, monitor, retry, and log workflows across environments.
Used by: Data teams across fintech, govtech, health, AI startups.
Roles: Data Engineer, MLOps Engineer.
Skills to pair: Airflow 2.0, Prefect flows, Kubernetes Executor, sensors, retries.
4. Kafka / Kafka Streams
What it is: Distributed log and event streaming platform.
Why it matters: Enables real-time data pipelines, change data capture, and stream processing.
Used by: Revolut, Tesco, Experian, gaming and trading platforms.
Roles: Streaming Data Engineer, Kafka DevOps, Event-Driven Architect.
Skills to pair: Confluent, Kafka Connect, KSQLDB.
5. Delta Lake / Iceberg
What it is: ACID-compliant layers for modern data lakes.
Why it matters: Brings data quality, versioning and schema enforcement to lakehouse architectures.
Used by: Databricks customers, big analytics platforms.
Roles: Lakehouse Engineer, ML Platform Engineer.
Cloud & Storage Platforms to Learn
▸ Snowflake
What it is: Cloud-native data warehouse known for simplicity and scalability.
Why it matters: Becoming the de facto warehouse for startups, banks, and retail.
Used by: GSK, Gousto, Capita, Revolut.
Roles: Snowflake Engineer, Analytics Engineer.
Skills to pair: SQL, dbt, Snowpipe, Streams, Tasks.
▸ Databricks
What it is: Unified platform for analytics, ML, and lakehouse architecture.
Why it matters: Powers high-scale pipelines and ML platforms.
Used by: Shell, HSBC, AstraZeneca, government departments.
Roles: ML Platform Engineer, Data Engineer.
Skills to pair: Spark, MLflow, Delta Live Tables.
▸ BigQuery (GCP)
Why it matters: Serverless analytics platform ideal for large datasets and fast queries.
Used by: Cambridge Analytica, games studios, startups.
Roles: Data Analyst, GCP Engineer.
Skills to pair: SQL, dbt, GCP IAM, Looker.
▸ Redshift / Synapse
Used in AWS & Azure environments for companies standardised on those platforms.
Observability, Quality & Automation Tools
▸ Great Expectations / Soda.io
What it is: Data testing and validation frameworks.
Why it matters: Ensures pipeline trustworthiness and alerts on schema or value errors.
Used by: Regulated industries, data quality-first organisations.
Roles: Data Reliability Engineer, Analytics Engineer.
▸ Monte Carlo / Datafold
What it is: Data observability platforms.
Why it matters: Tracks freshness, volume, lineage, and drift.
Used by: Modern data teams scaling in size and complexity.
Roles: DataOps Engineer, Platform Engineer.
▸ Terraform / Pulumi
What it is: Infrastructure-as-code tools for automating data stack deployments.
Why it matters: Enables cloud-native reproducibility and rapid provisioning.
Used by: DevOps, data infrastructure, platform teams.
Roles: Data Infra Engineer, Platform DevOps.
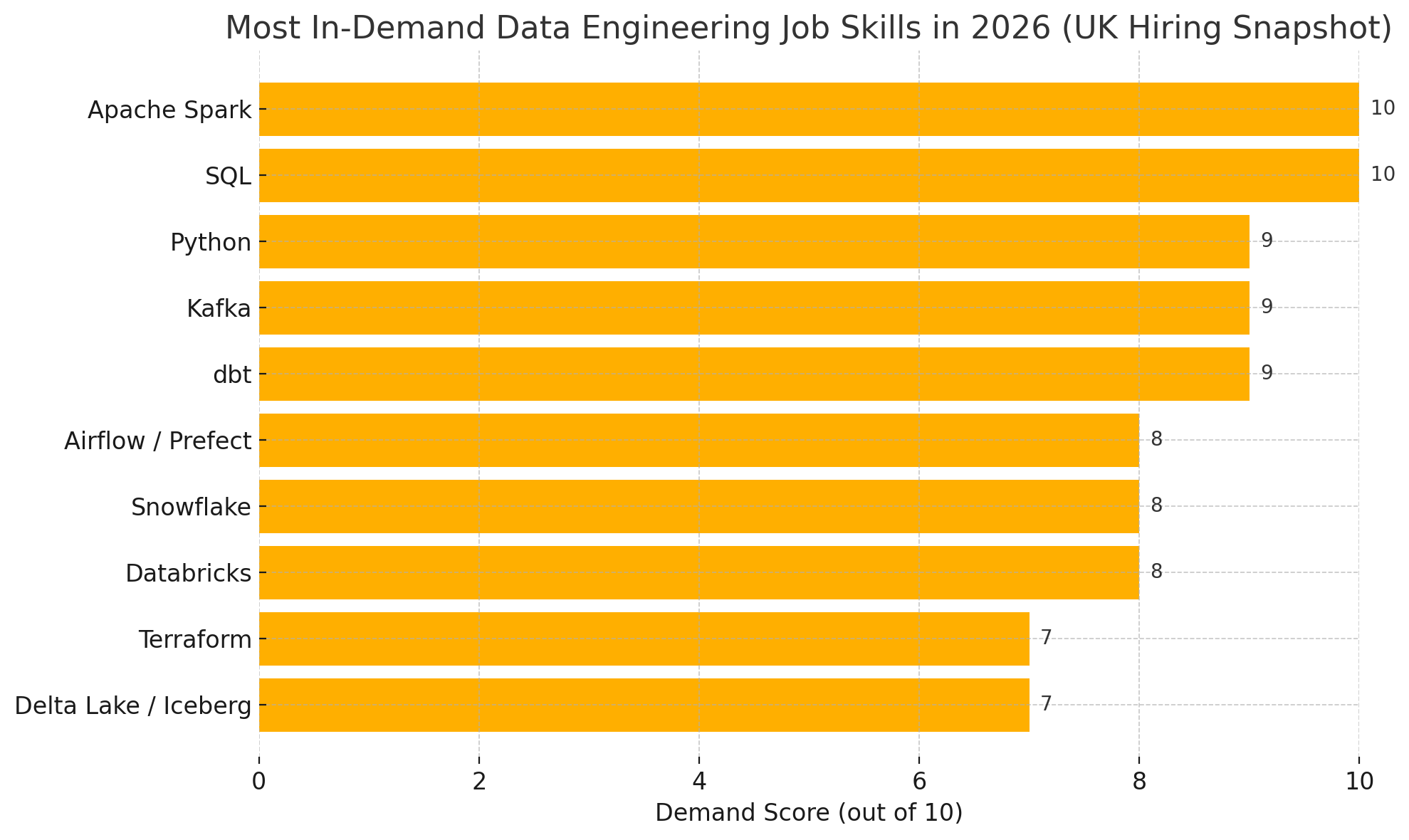
Most In-Demand Data Engineering Job Skills in 2026 (UK Hiring Snapshot Forecast)
Below is a visual snapshot of the languages, tools, and platforms that UK employers are looking for in data engineers:
How to Future-Proof Your Data Engineering Career in 2026
Master Modern Data Stacks
Learn how Spark, Kafka, dbt, and Airflow fit together—and when to use them.Build CI/CD for Data Pipelines
Use Git-based workflows and embrace testing, observability, and modular design.Certify Where It Counts
Snowflake, Databricks, and cloud platform certifications (AWS/GCP/Azure) are increasingly requested in UK job ads.Get Fluent in SQL + Python
These remain the backbone of most data roles—don't skip fundamentals.Join UK Data Communities
Attend meetups and conferences like Big Data LDN, PyData London, and dbt Meetups. Follow groups like the BCS Data Management Specialist Group.
Where to Find Data Engineering Jobs in the UK
🔎 Explore the latest listings at www.dataengineeringjobs.co.uk—from junior ETL developer roles to senior cloud data engineers. We list verified UK-only jobs across tech, finance, health, public sector, and AI startups.
Conclusion: Your Data Engineering Toolkit for 2026
In a world where AI, business intelligence, and operations all rely on clean, fast data—your work as a data engineer has never been more crucial. Master the modern tools, build scalable solutions, and stay ready for what’s next.
Use this Data Engineering Jobs Skills Radar 2026 as your yearly reference, and check back each quarter as the tech landscape evolves.
Subscribe to the newsletter for fresh roles, career advice, salary benchmarks & exclusive interviews with UK data leaders.


:quality(80))
:quality(80))
:quality(80))